导言
2018年 kubecon 大会上,阿里的陈俊大佬分享 Node-operator 的主题让我印象深刻,回来之后开始着手研究 Operator。正好当时老板希望能够将公司正在使用的 Nosql 组件容器化,顺势给老板安利一波 Operator 的思想。随后以 opentsdb 的容器为开端,后续完成一系列组件容器化,一路走来不断学习和借鉴其他 operator 的先进经验。Zookeeper作为最新完成 operator 化的组件,除了可以快速部署以外,还实现了 Operator 对 scale up/down 的进度干预,控制 rolling 的重启顺序,感知组件实际运行状态等,具体实现请阅读对于相关章节。
功能需求
目前 operator 主要实现如下功能:
- 快速部署
- 安全伸缩容
- 自动化监控
- 故障自愈
- 可视化操作
CRD
Operator 设计第一步是定义声明式接口的 Item,spec 主要包含节点资源、监控组件、副本数、持久化存储。
apiVersion: database.ymm-inc.com/v1beta1
kind: ZooKeeper
metadata:
name: zookeeper-sample
spec:
version: v3.5.6
cluster:
name: test
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 2000m
memory: 2Gi
exporter:
exporter: true
exporterImage: harbor.ymmoa.com/monitoring/zookeeper_exporter
exporterVersion: v3.5.6
disableExporterProbes: false
nodeCount: 3
storage:
size: 100Gi
架构图
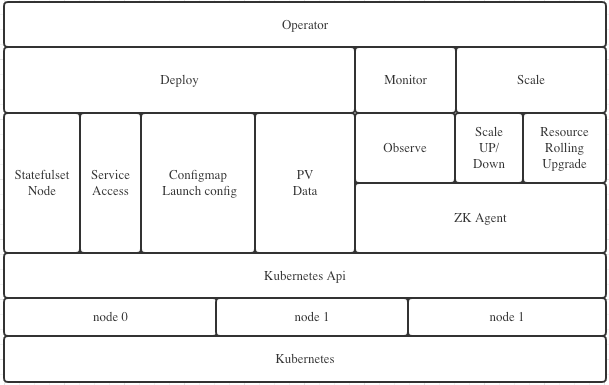
Operator 主要包含:Deploy、Monitor、Scale 三个大模块。
- Deploy:主要用于生成和创建 Statefulset、Service、ConfigMap、PV 等原生资源,用于快速部署 zookeeper 集群。
- Monitor:主要用于生成和创建 ServiceMonitor、PrometheusRule 资源,用于自动化注册 target、添加告警策略,实现对集群的监控和告警。
- Scale:主要用于把控扩缩容以及滚动升级的进度,确保以最少的主从切换完成重启。
具体方案
快速部署
基本知识
-
Kubernetes Labels
- Labels:是一对 key/value,被关联到特定对象上,标签一般用来表示同一类资源,用来划分特定的对象,一个对象可以有多个标签,但是,key 值必须是唯一的。这里我们将在 list-watch 的时候用这个 labels 进行过滤,从所有的 Kubernetes event 中过滤出符合特定 label 的 event,用来触发 operator 的主流程。
-
Kubernetes Informer
-
watch:可以是 Kubernetes 内建的资源或者是自定义的资源。当 reflector 通过 watch API 接收到有关新资源实例存在的通知时,它使用相应的列表 API 获取新创建的对象,并将其放入 watchHandler 函数内的 Delta Fifo 队列中。
-
Informer:informer 从 Delta Fifo 队列中弹出对象。执行此操作的功能是 processLoop。Base controller 的作用是保存对象以供以后检索,并调用我们的控制器将对象传递给它。
-
Indexer:索引器提供对象的索引功能。典型的索引用例是基于对象标签创建索引。 Indexer 可以根据多个索引函数维护索引。Indexer 使用线程安全的数据存储来存储对象及其键。 在 Store 中定义了一个名为 MetaNamespaceKeyFunc 的默认函数,该函数生成对象的键作为该对象的 / 组合。
-
Labels
labels:
app: zookeeper
app.kubernetes.io/instance: zookeeper-sample
app.kubernetes.io/managed-by: zookeeper-operator
app.kubernetes.io/name: zookeeper
app.kubernetes.io/part-of: zookeeper
component: zookeeper
zookeeper: zookeeper-sample
节点部署
容器分类
- InitContainer
- 配置文件初始化容器,主要用于 zk config 文件复制到工作区域。
- Container
- 主进程容器
- 监控容器
- Agent
初始化容器
zoo.cfg.dynamic,这个文件同样以 configmap 方式挂入主容器,主要用于zk节点发现和注册,下面将详细介绍下这个zk 3.5之后的特性。
- 具体可以参考 ZooKeeper 动态重新配置
server.1=zookeeper-sample-0.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.2=zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.3=zookeeper-sample-2.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.4=zookeeper-sample-3.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
server.5=zookeeper-sample-4.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181
- 更新目录权限
设置 data 和 logs 目录的权限,确保 zk 能够正常启动。
echo "chowning /data to zookeeper:zookeeper"
chown -v zookeeper:zookeeper /data
echo "chowning /logs to zookeeper:zookeeper"
chown -v zookeeper:zookeeper /logs
主进程容器
- 环境变量
POD_IP、POD_NAME,主要将 node 的 pod ip 和名称传到 pod 内部,方便容器内部调用。
ZK_SERVER_HEAP,这变量为限制 zk 启动 heapsize 大小,由 operator 根据 request 内部大小设置,zk启动会读取这个变量。
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: ZK_SERVER_HEAP
value: "2048"
- name: ZK_CLIENT_HEAP
value: "512"
- Readiness探针
主要通过 zk 客户端端口传入 ruok 命令,检查返回码,返回 imok 认为 zk node 已经准备完毕,zk node 将会被更新到上面说到的 zoo.cfg.dynamic 文件,zk cluster 将会自动发现该节点。
ZK_CLIENT_PORT=${ZK_CLIENT_PORT:-2181}
OK=$(echo ruok | nc 127.0.0.1 $ZK_CLIENT_PORT)
if [ "$OK" == "imok" ]; then
exit 0
else
exit 1
fi
监控容器
github 项目(https://github.com/dabealu/zookeeper-exporter) exporter 跟随主进程一同启动,后续会介绍如何注册到 prometheus target 以及告警策略。
访问控制
- 暴露端口
9114:该端口为 exporter 服务端口,通过 servicemonitor 注册 prometheus target 时将通过 labels 匹配该端口。
1988:该端口为 zk-agent 服务端口,通过该接口 operator 可以查询到当前节点运行状态,后面会详解介绍。
2181:该端口为 zk 客户端端口,该端口创建 Kubernetes headless 模式 svc,方便客户端一次获取所有节点 ip。
3888:选举 leader 使用
2888:集群内机器通讯使用( Leader 监听此端口)
ports:
- name: client
port: 2181
protocol: TCP
targetPort: 2181
- name: server
port: 2888
protocol: TCP
targetPort: 2888
- name: leader-election
port: 3888
protocol: TCP
targetPort: 3888
- name: http-metrics
port: 9114
protocol: TCP
targetPort: 9114
- name: http-agent
port: 1988
protocol: TCP
targetPort: 1988
- 暴露方式
这里主要 kubernetes service 的两种模式:Headless 和 Cluster
Headless Services:简单而言就是,每次访问 headless service,kube-dns 将返回后端一组 ip,在我们这种场景下,即会返回 es 所有节点 ip 给客户端,再由客户端自己判断通过哪个 ip 访问 es 集群。
Cluster:这种模式是默认配置,创建此类 service 之后,将分配一个 cluster ip,这个 ip 类似 vip,每次访问这个 service name,kube-dns 将会随机返回一个节点 ip。
operator 在创建 service 的时候,上面两种都会创建,headless 类型主要给 kubernetes 内部应用访问,cluster 类型主要通过 NodePort 暴露给外部应用访问。
配置信息
- 配置文件
autopurge.purgeInterval=24
autopurge.snapRetainCount=20
initLimit=10
syncLimit=5
skipACL=yes
maxClientCnxns=300
4lw.commands.whitelist=cons, envi, conf, crst, srvr, stat, mntr, ruok
tickTime=2000
dataDir=/data
dataLogDir=/logs
reconfigEnabled=true
standaloneEnabled=false
dynamicConfigFile=/conf/zoo.cfg.dynamic.c00000002
数据存储
- PersistentVolume
StorageClass PROVISIONER: diskplugin.csi.alibabacloud.com,阿里云CSI插件实现了 Kubernetes 平台使用阿里云云存储卷的生命周期管理,支持动态创建、挂载、使用云数据卷。 当前的 CSI 实现基于kubernetes 1.14以上的版本。
云盘 CSI 插件支持动态创建云盘数据卷、挂载数据卷。云盘是一种块存储类型,只能同时被一个负载使用(ReadWriteOnce)。
operator 会将 CRD 中配置的 pvc 信息,透传到 sts 中去,并挂载到 zk data 目录下 。
自动化监控
监控注册
ServiceMonitor
selector.matchLabels:这里通过 zookeeper: zookeeper-sample 来匹配 service。
port: http-metrics:这里通过匹配 service 中到 port name 来注册到 prometheus target。
operator 调用 prometheus-operator client 完成 ServiceMonitor 资源的创建,实现新建zk集群自动注册到prometheus的功能。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: zookeeper
app.kubernetes.io/instance: zookeeper-sample
app.kubernetes.io/managed-by: zookeeper-operator
app.kubernetes.io/name: zookeeper
app.kubernetes.io/part-of: zookeeper
component: zookeeper
zookeeper: zookeeper-sample
name: zookeeper-sample
namespace: default
spec:
endpoints:
- interval: 30s
port: http-metrics
namespaceSelector: {}
selector:
matchLabels:
zookeeper: zookeeper-sample
PrometheusRule
operator 调用 prometheus-operator client 完成 PrometheusRule 资源的创建,实现将告警策略自动注册到 prometheus。
告警策略中的 dingtalkRobot 标签,主要用来重定向告警信息到指定钉钉群中,这里可以添加多个钉钉群机器人。
安全伸缩容
扩缩节点
-
更新 Zookeeper CR 中 spec.cluster.nodeCount 配置。
-
触发 operator 主流程,判断期望副本数大于实际副本数继续流程,否则退出主流程。
-
更新 zk 集群 records,提交两种 record:
-
Zookeeper upscale from 3 to 4.
-
Zookeeper Statefulset %s already update.
-
-
更新 zk 集群 StatefulSet 资源,StatefulSet 控制器将会新建节点,zk 将新建节点加入集群中,数据将会自动做同步。
-
Reconfig 模块将从集群中添加或者剔除节点
扩资源
-
更新 Zookeeper CR 中 spec.node.resources 配置。
-
如果zk节点数与期望节点数不一致,退出主流程,直到节点数一致,所有 pod 全部 ready。
-
通过节点数量检查之后,更新 StatefulSet 资源,由于我们这边 StatefulSet 设置的 RollingUpdate 策略为 OnDelete,即更新 StatefulSet 配置之后,StatefulSet 将不会主动重启节点以完成升级,需要我们自己手动去重启节点。
-
获取当前集群中节点角色,将 leader 节点放到最后重启,尽量减少集群不可用时间。
-
operator 比对 StatefulSet 和 pod resourceVersion值,如果不一致将节点加入到需要重启节点列表中。
-
operator 执行对节点如下检查项:
-
当前重启中对节点是否超过 MaxUnavailable 值,目前 MaxUnavailable 值默认为1.
-
跳过节点状态为 Terminating 的节点。
-
-
从重启节点中取一个节点,调用 kubernetes 接口,执行重启操作。
-
第一个节点重启完成之后,将 requeue 主流程,继续其他节点重启。
-
所有节点全部重启完成,滚动升级成功。
故障自愈
Observer
-
operator 会为每一个创建的 zk 集群启动一个 observer,每个 observer 将会启动两个 goroutine:
-
GetClusterStatus,获取 zk-agent /status 接口数据。
-
GetClusterUp,获取 /runok 接口数据。
-
-
operator 将每10秒获取集群最新状态,包括集群状态、node 节点数、leader 节点等。
-
operator 获取到最新集群状态之后,将更新CR的 status 中,达到实时更新 CR 中 zk 集群状态的功能,效果如下图。
status:
availableNodes: 3
leaderNode: zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local
- 如果zk集群被销毁, operator 将调用 finalizers 方法停止 observer 协程。
触发主流程
-
operator 控制器在初始化的时候,将 watch 一个自定义的 event channel,等待 event 通过 channel 传递过来,触发主控流程执行。
-
observer 初始化的时候,创建一个 listeners 函数数组,用于 observer 状态刷新时候调用,每新建一个 zk 集群将加入一个 listener。
-
observer 执行一次,listeners 数组中的函数将会执行一次,获取最新各个 zk 集群的 health 状态。
-
listeners 数组的函数将判断,集群新状态与老状态是否一致,一致则返回 nil,否则进一步处理。
-
如果状态不一致将传值到 event channel,由 watch 消费以触发 operator 主控流程执行。
可视化操作
可视化操作,主要实现一下功能:
- zk 集群的查询、创建、伸缩、资源调整
- 支持多 kubernetes 环境
- 支持集群监控展示
多kubernetes环境
对于多 kubernetes 环境的支持,主要通过在每个环境部署 agent 组件,组件通过 rbac 进行授权,确保agent组件只能操作指定资源。将 agent 注册到管理平台,管理平台按照环境请求不同环境接口即可。
接口列表
| 模式 | 接口 | 说明 | 备注 |
|---|---|---|---|
| GET | /zookeeper/list | 查询所有zookeeper集群信息 | |
| POST | /zookeeper/info | 查询单个zookeeper集群信息 | |
| POST | /zookeeper/create | 创建单个zookeeper集群 | |
| POST | /zookeeper/update | 更新单个zookeeper集群 | |
| POST | /zookeeper/delete | 销毁单个zookeeper集群 |
参数校验
Admission Webhooks
- ValidatingWebhook:主要实现验证检测,即检查通过 kubernetes API client 提交到CR参数是否合法,如果不符合要求直接拒绝资源创建。检查项如下:
- 检查节点资源,request CPU/mem 是否小于 limit CPU/mem
- MutatingWebhook:主要实现注入默认参数,即检查到提交参数缺少一些关键性参数,将由 webhook 补齐并注入到创建资源中。补全项如下:
- 节点资源限制,比如request cpu/mem和limit cpu/mem。
- exporter配置,默认开启exporter,
Exporter: true,
ExporterImage: "harbor.ymmoa.com/monitoring/zookeeper_exporter",
ExporterVersion: "1.1.0",
DisableExporterProbes: false,
升级策略
StatefulSets 提供了多种升级策略:OnDelete,RollingUpdate,RollingUpdate with partition。
OnDelete的一般方法
使用 OnDelete,除非 Pod 的数量高于预期的副本数,否则 StatefulSet 控制器不会从 StatefulSet 中删除 Pod。
Operator 决定何时要删除 Pod。一旦删除,便会由 StatefulSet 控制器自动重新创建一个 Pod,该 Pod 具有相同的名称,但是最新的规范。
我们的操作员永远不会创建 Pod,但是当我们决定准备删除 Pod 时,它将负责 Pod 的删除。
当对 StatefulSet 进行修改时(例如,更改 Pod 资源限制),我们最终得到一个新的 revision(基于模板规范的哈希值)。
查看 StatefulSet 状态,我们可以获得当前的修订版(currentRevision: zookeeper-sample-7b889dd5b4),使用该修订版的容器的数量以及仍在使用旧修订版的容器的数量(updateRevision: zookeeper-sample-74597f9b9d)。
通过列出该 StatefulSet 中的 Pod,我们可以检查每个 Pod(metadata.labels[“controller-revision-hash”]: “zookeeper-sample-7b889dd5b4”)的当前版本。
RollingUpdate.Partition 方法
使用此策略,我们定义了一个 partition 索引:这允许使用 StatefulSet 控制器替换序数高于此索引的 Pod。
例如,如果我们有一个带有5个副本的 StatefulSet:
- zookeeper-sample-0
- zookeeper-sample-1
- zookeeper-sample-2
- zookeeper-sample-3
- zookeeper-sample-4
如果分区索引为3,则允许 StatefulSet 控制器自动删除然后重新创建 Pod zookeeper-sample-3 和 zookeeper-sample-4。
在此模式下,操作员永远不会删除 Pod。它所做的就是:
- 当应添加新容器或应除去容器时,更新 StatefulSets 副本
- 当应更换某些 Pod 时更新分区索引
要对上面的 StatefulSet 进行滚动升级,我们将从索引开始5,确保4可以安全地替换 Pod ,然后将索引更新为4。这将触发更换 Pod。
OnDelete 除了不显式删除 Pod 而是管理索引外,其他逻辑与适用相同。
Agent
zk agent 作为 sidecar 伴随主容器一并启动,提供如下接口:
- status:返回宿主 zk 节点当前运行状态,参考 zk srvr 命令。
- runok:返回宿主 zk 节点是否正常运行且无错误,参考 zk ruok 命令。
- health:返回 agent 运行状态,用于 agent 的心跳检测。
- get:返回 zk 集群节点列表,查询 /zookeeper/config 文件。
- add:增加节点到 zk 集群中,主要依赖 zk reconfigure 特性,集群扩容时使用。
- del:从现有 zk 集群中删除某个节点,如果删除节点是主节点,会先做主节点切换,之后才会移除节点,集群缩容时使用。
接口列表
| 模式 | 接口 | 说明 | 备注 |
|---|---|---|---|
| GET | /status | getZkStatus | |
| GET | /runok | getZkRunok | |
| GET | /health | Health | |
| GET | /get | getMember | |
| POST | /add | addMember | |
| POST | /del | delMember |
GET
/status, 获取当前 zk 节点运行状态,字段含义对照 mntr 查看信息,包括如下字段:
{
"Sent": 1617,
"Received": 1618,
"NodeCount": 5,
"MinLatency": 0,
"AvgLatency": 2,
"MaxLatency": 5,
"Connections": 1,
"Outstanding": 0,
"Epoch": 14,
"Counter": 82,
"BuildTime": "2019-10-08T20:18:00Z",
"Mode": 2, //0表示Unknown,1代表Leader,2代表follower
"Version": "3.5.6-c11b7e26bc554b8523dc929761dd28808913f091",
"Error": null
}
/runok,获取当前节点是否正常启动。
/health,获取 zk-agent 是否正常启动。
/get,获取当前 Reconfig 动态配置节点信息。
{
"record": "server.1=zookeeper-sample-0.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nserver.2=zookeeper-sample-1.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nserver.3=zookeeper-sample-2.zookeeper-sample.default.svc.cluster.local:2888:3888:participant;0.0.0.0:2181\nversion=c00000002"
}
POST
/add,获取客户端传入需要新增的节点信息,并更新到动态节点配置中。
/del,获取客户端传入需要删除到节点信息,并更新到动态节点配置中。传入值参考 add 接口格式。
OAM对接
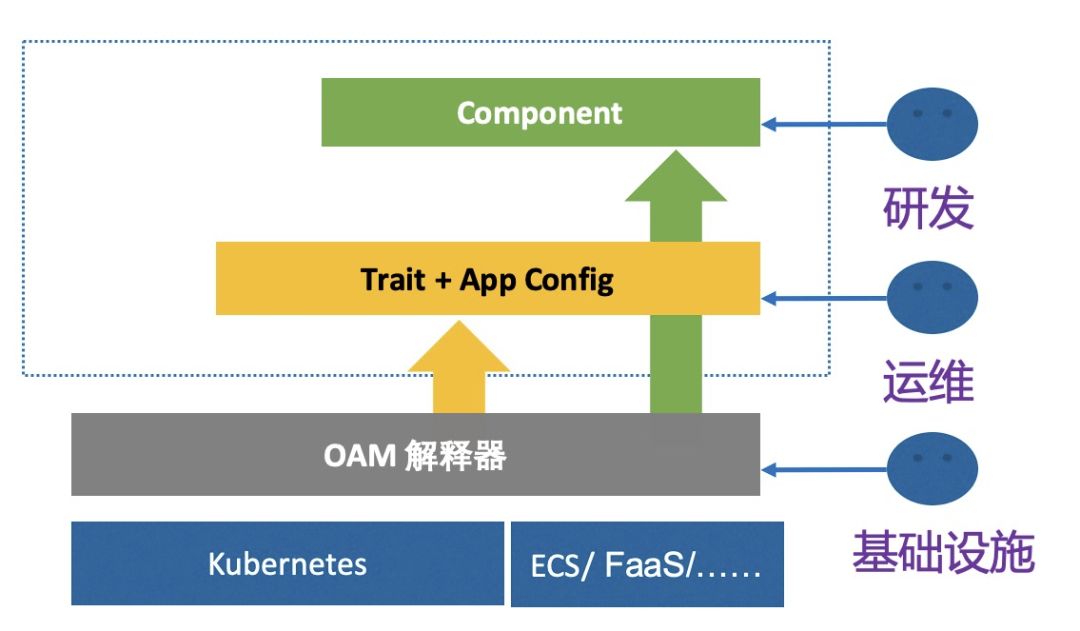
OAM 是一个专注于描述应用的标准规范。有了这个规范,应用描述就可以彻底与基础设施部署和管理应用的细节分开。这种关注点分离(Seperation of Conerns)的设计好处是非常明显的。
应用组件(Components)
组件(Components):概念让平台架构师等能够将应用分解成成一个个可被复用的模块,这种模块化封装应用组成部分的思想,代表了一种构建安全、高可扩展性应用的最佳实践:通过一个完全分布式的架构模型,实现了应用组件描述和实现的解耦。
按照应用组件的定义,对应到目前zk operator的快速部署模块上,部署模块主要生成和创建原生资源,完成容器化zk集群搭建,并持续维持声明式定义的集群终态。部署模块可以单独定义CRD, 比如 workload.zookeeper.example.com。
应用运维特征(Traits)
运维特征(Traits):它们描述了应用在具体部署环境中的运维特征,比如应用的水平扩展的策略和 Ingress 规则,这些特征对于应用的运维来说非常重要,但它们在不同的部署环境里却往往有着截然不同的实现方式。
Traits则对应 zk operator 模块中的 伸缩、滚动升级两个模块,这两个模块可以抽出来定义为单独CRD,比如 scale.zookeeper.example.com 和 rolling.zookeeper.example.com。
小结
目前 zk operator 的实现能力也仅仅实现 部署、伸缩、滚动升级、监控等能力,还有很多模块可以做,比如:备份、重置、迁移、调度策略、暂停等等。